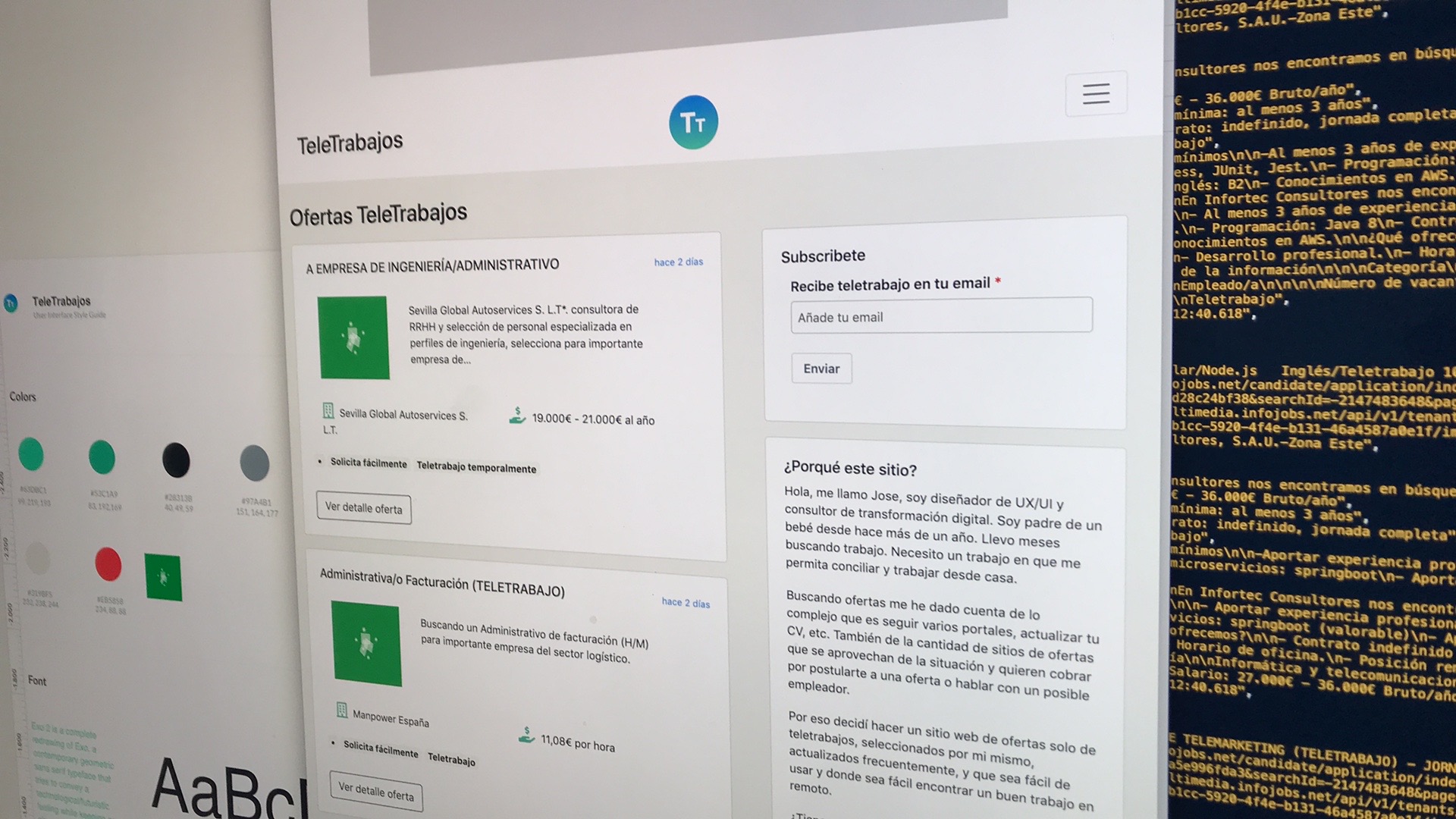
Agregador de contenidos
Cómo crear un agregador de contenidos con Hugo Parte 1
Hace poco me entro curiosidad por hacer un sitio web tipo agregador. Quería conocer un poco la tecnología detrás, y saber si podría hacerlo con Hugo. Llevo buscando trabajo unos meses y he decidido que voy a hacer un agregador de trabajos filtrando solo trabajos en remoto o teletrabajos.
Me puse manos a la obra y en pocos de días tenía el sitio funcionando con un montón de características implementadas. Claro que siempre hay más cosas que se pueden añadir, y las iremos añadiendo poco a poco.
Voy a intentar resumir como lo he hecho para completar el sitio agregador de contenidos con Hugo.
Agregar contenidos
No sé si técnicamente es lo mismo pero para ir probando como podría hacer empecé sacando las ofertas de trabajo de sitios web haciendo extracción de datos o scrapping. Para hacer scrapping de un sitio web hay multitud de herramientas y soluciones.
Creo que con Python o Ruby hay muchas soluciones de código libre para hacer esto mismo y además se puede automatizar mejor, por ejemplo: https://lobste.rs
Pero estamos con Hugo, y es un sitio estático, no tenemos una base de datos que alimentar ni esperar a qué realice complejas y largas peticiones. Necesitamos otra estrategia.
He pensado en hacer el scrapping con una herramienta que tenga los siguientes requisitos:
- Gratis
- Preferible interfaz gráfica GUI
- Curva de aprendizaje sencilla
Basado en estos requisitos he elegido Octoparse. Es muy fácil de usar ya que detecta los campos y crea los flujos de trabajo con bucles para capturar datos con paginación y profundizando en los listados de contenidos. Puedes crear una cuenta gratis y tener hasta 10 tareas gratis, que es como llaman a la configuración para extraer datos de un sitio web.
El plan es el siguiente:
- Entra en el listado de noticias de la web X
- Lee todos los campos del listado. Extrae datos.
- Mira en otras paginas usando paginación
- Pincha en un enlace de un elemento del listado para extraer datos del detalle de la entrada
- Extrae datos.
- Personaliza los campos de los datos extraídos.
- Ejecuta la tarea y genera un JSON con los datos.
Con Octoparse es muy fácil hacer todo esto, ya que todo es casi automático. Al registrarte para la cuenta gratis te ofrecen unos tutoriales muy sencillos para que arranques, pero casi que no los vas a necesitar porque ya te digo que es muy sencillo.
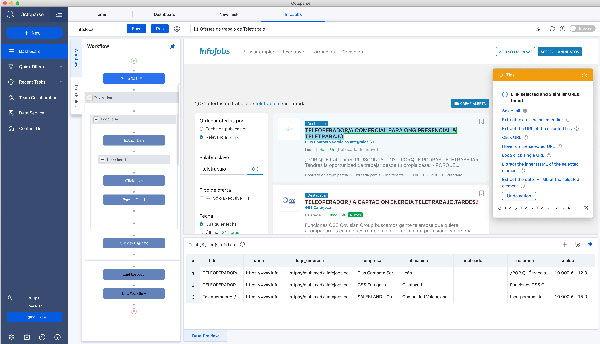
Lo único que sí he personalizado son los nombres de los campos que he extraído. Yo los he renombrado para unificar datos si uso varias fuentes. Recomiendo echar un vistazo a schema.org para ver la mejor forma de definir distintos tipos de contenido.
Bueno, si todo ha ido bien :) ahora tenemos un archivo JSON con los datos extraídos de la primera web, genial!
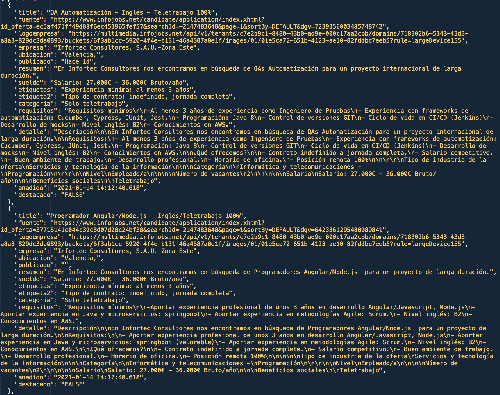
Ahora ya podríamos cargar esos contenidos en un plantilla HTML y tendríamos casi lista la página. Nooo, es broma, eso es una locura, podríamos acabar con un archivo JSON muy grande y sería complicado que el rendimiento fuera óptimo.
Podríamos hacer una web con una sola página y que cargara todos estos datos en un listado de manera asíncrona y quizás funcionara pero mi idea es crear una página por cada oferta de trabajo así que tenemos que encontrar algo que convierta este JSON en páginas estáticas en HUGO.
Por suerte eso esta entre las cosas que puedes hacer con GO y he encontrado un proyecto que se llama HUGOMPLATE qué integra GOMPLATE + HUGO, y hace exactamente esto, crea páginas en formato .md de un archivo JSON.
in: |
{{ range (datasource "posts") }}
{{ range . }}
{{ $file := .title | strings.Slug }}
{{ tmpl.Exec "postT" . | file.Write (print "outputs/localjson/" $file ".md") }}
{{ end }}
{{ end }}
datasources:
posts:
url: data/fuentedatos.json
outputFiles: ["json"]
templates:
- postT=gomplate/plantilladatos.tmpl
suppressEmpty: true
En realidad no he cambiado nada del proyecto HUGOMPLATE DEMO, simplemente lo he instalado desde el repositorio y he modificado la plantilla para crear los archivos md desde JSON. Esta plantilla la puedes encontrar en hugomplate-demo/gomplate-demo/templates/localjson.tmpl. La plantilla original es muy simple:
---
title: {{ .title }}
---
This is from a gompl plugin.
{{ .content }}
Vamos a modificarla con los campos que hemos extraído de nuestro scrap anterior. Yo he usado nombres en español para los campos pero creo que con los nombres en inglés es más fácil de gestionar, allá vosotros….
---
title: "{{ .title }}"
fuente: {{ .fuente }}
empresa: "{{ .empresa }}"
resumen: "{{ .resumen }}"
publicado: "{{ .publicado }}"
ubicacion: "{{ .ubicacion }}"
sueldo: "{{ .sueldo }}"
etiquetas: ["{{ .etiquetas }}", "{{ .etiqueta2 }}"]
categorias: ["{{ .categoria }}"]
logoempresa: "{{ .logoempresa }}"
anadido: {{ (time.Now).Format "02/01/2006" }}
date: {{ time.Now }}
destacado: false
validado: false
---
{{ .detalle }}
Ya veis que es muy sencilla, he cambiado algunas cosas y lo he hecho así rápido. Me he quedado con los campos que me interesaban por ahora de la extracción de datos, un par de etiquetas, una categoría, el logo y nombre de la empresa, el sueldo, la fuente y un baile de fechas con las que tendré que hacer magia. Esto pasa al tener fuentes diferentes, obviamente los datos son diferentes y para unificar tendremos que manipular algún dato, especialmente las fechas. También he añadido un par de campos para validado y destacado, espero hacer algo con esto luego.
Una cosa más, el archivo de datos JSON tiene que estar dentro de un array de posts para que el hugomplate convierta cada entrada en un post en Hugo.
{ posts: [
//de aqui pa abajo todos los posts
{
"title": "xxx",
"fuente": "xxx",
"logoempresa": "xxx",
"empresa": "xxx",
"ubicacion": "xxx",
"publicado": "xxx",
"resumen": "xxx",
"sueldo": "",
"etiquetas": "",
"etiqueta2": "",
"categoria": "",
"anadido": "xxx",
"detalle": "xxx",
"destacado": "",
"validadado": ""
},
{
//otro post
}
]
}
Si lo has preparado todo como arriba ya solo queda ejecutar gomplate en la raíz de hugomplate-demo y debería producir los post de hugo. Los archivos se exportan a la carpeta output.
mi-maquina:hugo-demo miusuario$ gomplate -V
23:22:33 DBG using config file cfgFile=.gomplate.yaml
23:22:33 DBG starting gomplate
23:22:33 DBG config is:
---
in: '{{ range...'
outputFiles: [json]
suppressEmpty: true
leftDelim: '{{'
rightDelim: '}}'
datasources:
posts:
url: file:///Volumes/HD/Users/USUARIO/Sites/teletrabajos/hugomplate-demo-master/hugo-demo/data/fuentedatos.json
header: {}
pluginTimeout: 5s
templates:
- postT=gomplate/plantilladatos.tmpl
build= version=3.8.0
23:22:33 DBG created data from config data="&{ctx:0xc00014ea50 Sources:map[posts:posts=file:///Volumes/HD/Users/USUARIO/Sites/teletrabajos/hugomplate-demo-master/hugo-demo/data/fuentedatos.json ()] sourceReaders:map[] cache:map[] extraHeaders:map[]}"
23:22:33 DBG completed rendering duration=0.070753795 errors=0 templatesRendered=1
Todavía no hemos creado la página con Hugo pero ya tenemos unos archivos .md con el formato de página de Hugo. En el próximo post vamos a empezar a montar la web con estos contenidos.
¿Qué te ha parecido hasta ahora? Deja tus comentarios abajo.